一、什么是主从复制?
MySQL 主从复制(Master-Slave Replication)是一种数据同步机制,通过将主数据库(Master)的增量数据实时同步到从数据库(Slave),实现数据的多副本存储。
核心逻辑:主库负责处理写操作(INSERT/UPDATE/DELETE 等),从库同步主库数据后可处理读操作,从而实现「读写分离」「负载均衡」「数据备份」等核心需求。
mysqldump解决了mysql数据库的备份,它只是基于某个时间点做备份,无法解决实时备份的问题,为了解决mysql实时备份的问题,mysql官方推出了mysql主从备份机制,可以让用户通过设置mysql主从来实现数据库实时备份。
1、MySQL服务器宕机怎么办,单点故障
2、数据的安全
通过多台机器实现一主多从的方式来实现数据备份,主服务器负责让用户读写数据,从服务器负责同步主服务器数据,也可以承担用户读的任务。
至少两台机器
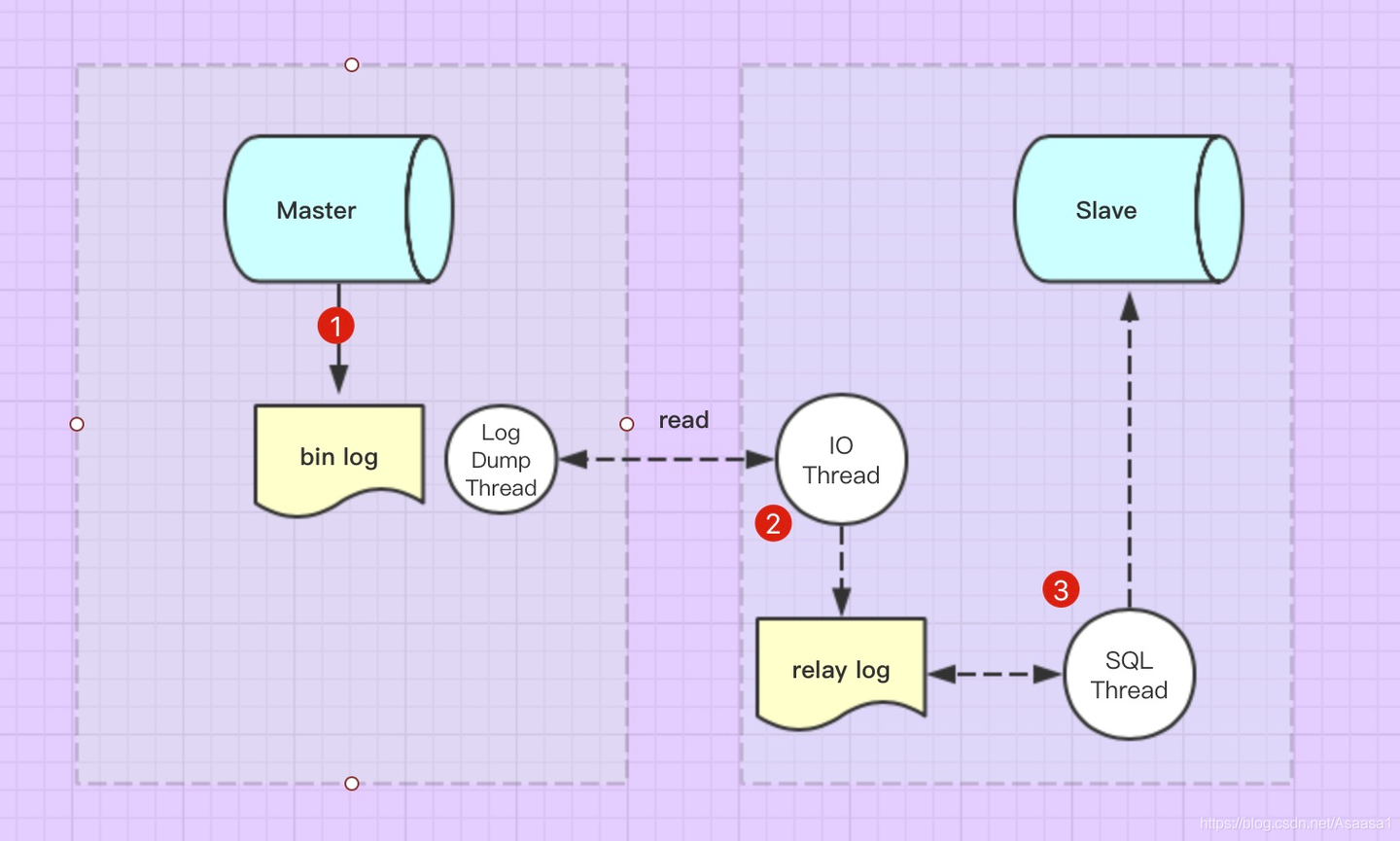
将主数据库的增删改查等操作记录到二进制日志文件中,从库接收主库日志文件,根据最后一次更新的起始位置,同步复制到从数据库中,使得主从数据库保持一致。
如上图所示,主从复制步简单描述:
- master服务器上的更新事件(所有DDL和DML操作)会按照顺序写入binlog中,当slave服务器连接到master服务器后,master服务器会为slave服务器开启binlog dump线程,该线程会去读取bin-log日志。
- slave服务器连接到master服务器后,slave服务器开启一个I/O线程请求master服务器的binlog dump线程,读取bin-log日志,然后将master服务器上的变更记录写入slave服务器的的relay log日志中。
- slave还会开启一个SQL线程,实时监控relay-log日志内容是否有变化。如果有变化,将其解析成SQL语句,在slave服务器上重新执行一遍。
从上面的分析,可以知道,整个MYSQL主从复制一共开启了3个线程:master服务器开启了一个 dump线程,slave服务器开启了一个 IO线程 和 一个SQL线程。
二、主从复制的核心目标
- 读写分离:主库承担写操作,从库分担读压力(如查询),提升系统吞吐量;
- 数据备份:从库作为主库的副本,避免单库故障导致数据丢失;
- 高可用:主库故障时,可切换到从库继续提供服务(需配合故障转移工具);
- 负载均衡:多从库架构下,将读请求分散到不同从库,降低单库压力。
三、主从复制的核心原理(3 大步骤详细版)
主从复制的本质是「主库记录操作日志,从库同步并执行日志」,整个过程分为 3 个关键步骤,依赖 3 类日志和 3 种线程协同工作。
1. 主库:记录二进制日志(binlog)
当主库执行写操作(如增删改、建表等)时,会先将操作以「事件(Event)」的形式记录到二进制日志(binlog) 中,再执行实际操作。
- binlog 作用:记录主库所有数据变更操作,是主从同步的「数据源」;
- binlog 格式:
STATEMENT:记录 SQL 语句(可能存在主从数据不一致,如使用NOW()函数);ROW:记录每行数据的变更细节(最安全,避免不一致,但日志体积大);MIXED:默认用 STATEMENT,复杂场景自动切换为 ROW(平衡安全性和日志体积);- 关键:binlog 是主从复制的基础,主库必须开启 binlog(
log_bin=ON)。
2. 从库:拉取主库 binlog 并写入中继日志(relay log)
从库启动后,会创建一个IO 线程,负责连接主库并拉取 binlog:
- 从库 IO 线程通过主库的「授权用户」连接主库,发送请求:“请把 binlog 从某个位置开始发给我”;
- 主库收到请求后,启动dump 线程,根据从库的请求,将 binlog 中指定位置后的事件逐批发送给从库;
- 从库 IO 线程接收主库发来的 binlog 事件,写入本地的中继日志(relay log) 中(中继日志是 binlog 的“副本”,格式与 binlog 一致)。
3. 从库:执行中继日志,同步数据
从库同时会创建一个SQL 线程,负责读取中继日志并执行其中的操作:
- SQL 线程不断检测中继日志,一旦有新的 binlog 事件,就按顺序执行(模拟主库的写操作);
- 执行完成后,从库的数据与主库保持一致。
四、核心组件详解
1. 关键日志
- 二进制日志(binlog):主库生成,记录所有数据变更操作(DDL/DML),是同步的“源数据”;
- 中继日志(relay log):从库本地存储,临时保存从主库拉取的 binlog 事件,避免直接操作主库 binlog 导致的冲突;
- 位置信息(binlog 文件名 + 偏移量):主库的 binlog 按文件存储(如
mysql-bin.000001),每个事件在文件中有具体偏移量(pos),从库通过记录“最后同步的文件名和 pos”,确保下次从断点继续同步。
2. 核心线程
| 线程 | 所属库 | 作用 |
|---|---|---|
| Dump 线程 | 主库 | 响应从库 IO 线程的请求,传输 binlog 事件 |
| IO 线程 | 从库 | 连接主库,拉取 binlog 并写入中继日志 |
| SQL 线程 | 从库 | 读取中继日志,执行事件同步数据 |
五、主从复制的配置要点
1. 主库配置
-
开启 binlog:
log_bin = /usr/local/mysql/data/mysql-bin(指定 binlog 存储路径); -
设置唯一 server-id:
server-id = 1(主从库 server-id 必须不同); -
授权从库连接用户:
CREATE USER 'repl'@'从库IP' IDENTIFIED BY 'password'; -- 创建复制用户
GRANT REPLICATION SLAVE ON *.* TO 'repl'@'从库IP'; -- 授予复制权限
2. 从库配置
-
设置唯一 server-id:
server-id = 2; -
配置主库信息(通过
CHANGE MASTER TO语句):
CHANGE MASTER TO
MASTER_HOST = '主库IP',
MASTER_USER = 'repl',
MASTER_PASSWORD = 'password',
MASTER_LOG_FILE = '主库当前binlog文件名', -- 如 mysql-bin.000001
MASTER_LOG_POS = 起始偏移量; -- 如 154(从该位置开始同步)
-
启动从库复制线程:
START SLAVE; -
检查状态:
SHOW SLAVE STATUS\G(需确保Slave_IO_Running和Slave_SQL_Running均为Yes)。
六、复制类型(按同步方式分类)
1. 异步复制(默认)
- 流程:主库执行完写操作 → 写入 binlog → 立即向客户端返回成功(不等待从库同步);
- 优点:性能好(主库无等待);
- 缺点:主库崩溃时,可能有数据未同步到从库,导致数据丢失。
2. 半同步复制(Semi-Sync)
- 流程:主库执行完写操作 → 写入 binlog → 等待至少一个从库收到 binlog 并写入中继日志 → 向客户端返回成功;
- 优点:数据安全性高于异步(至少一个从库有备份);
- 缺点:性能略低于异步(主库需等待从库确认)。
3. 全同步复制(Full-Sync)
- 流程:主库执行完写操作 → 等待所有从库执行完 binlog 事件并返回成功 → 向客户端返回成功;
- 优点:数据零丢失(主从数据完全一致);
- 缺点:性能差(主库等待时间长,适合对数据一致性要求极高的场景)。
七、常见架构
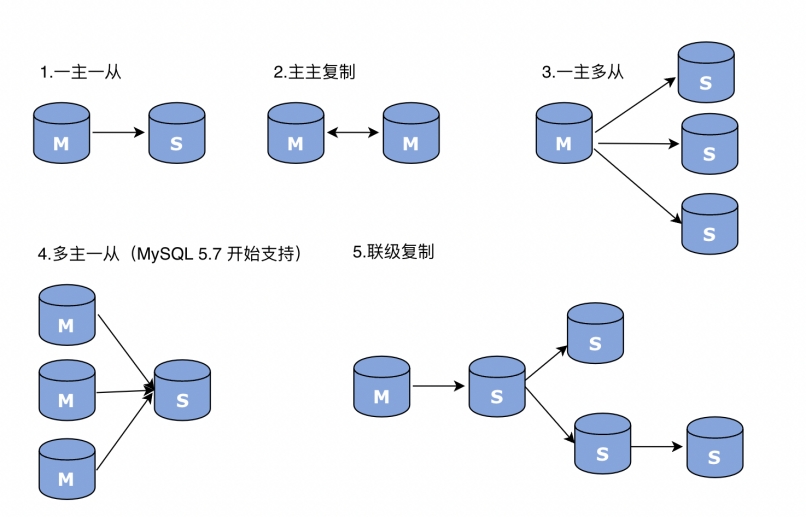
- 一主一从:最简单架构,主库写,从库读+备份;
- 一主多从:主库写,多从库分担读压力(适合读密集场景);
- 级联复制(主→从→从):主库只同步给一个从库(二级主库),再由二级主库同步给其他从库,减轻主库的 dump 线程压力;
- 双主复制:两个主库互为主从,均可写操作(需避免冲突,适合写分散场景)。
八、总结
MySQL 主从复制的核心是「binlog 日志同步」,通过 3 大步骤(主库写 binlog → 从库拉取 binlog 到中继日志 → 从库执行中继日志)实现数据一致。
其价值在于:
- 实现读写分离,提升系统吞吐量;
- 提供数据多副本,增强安全性;
- 支持故障转移,提高可用性。
理解主从原理是掌握 MySQL 高可用架构(如 MGR、ProxySQL、MyCAT 等)的基础,实际应用中需根据业务场景选择复制类型和架构。
九、实战
(一) 一主一从配置
1.服务器准备
| 服务器IP | 角色 | 主机名 |
|---|---|---|
| 192.168.8.100 | Master1(主) | master01 |
| 192.168.8.101 | Slave1(从) | slave01 |
2.数据库安装(mysql8.0.20)
# 执行MySQL安装脚本
bash mysql_install.sh
3.主库配置
安装完后,配置 my.cnf
vim /etc/my.cnf
[mysqld]
... # 省略
# 主从复制-主机配置
# 主服务器唯一ID
server-id=1
# 启用二进制日志
log-bin= mysql-bin
# 在数据目录创建日志等价于 log-bin=/usr/local/mysql/data/mysql-bin
# 设置不要复制的数据库(可设置多个)
binlog-ignore-db=sys
binlog-ignore-db=mysql
binlog-ignore-db=information_schema
binlog-ignore-db=performance_schema
# 设置需要复制的数据库(可设置多个)
# binlog-do-db=test
# 设置logbin格式
binlog_format=STATEMENT
binlog_format=STATEMENT 在这种设置下,MySQL将以“语句级别”记录二进制日志,也就是记录执行的SQL语句,而不是记录实际数据行的更改。
这种设置相对较简单,在涉及到数据库复制和事务的情况下有可能数据不同步。
除了STATEMENT格式外,MySQL还支持ROW和MIXED格式:
ROW格式记录了对数据行的更改。MIXED格式则是根据操作的类型(语句或行)来灵活选择。
4.从库配置
vi /etc/my.cnf
[mysqld]
...
# 在之前配置下方编写
# 主从复制-从机配置
# 从服务器唯一ID
server-id=2
# 启用中继日志
relay-log= mysql-relay
# 在数据目录创建日志等价于 relay-log= /usr/local/mysql/data/mysql-relay
重启两台服务器上的mysql
/etc/init.d/mysqld restart
# 或者
systemctl restart mysqld
5.关闭主从数据库服务器防火墙或开放3306端口
# 查看防火墙状态
systemctl status firewalld
# 关闭防火墙
systemctl stop firewalld
6.主数据库创建用户slave并授权
# 在主数据库端(192.168.8.100)
# 登录mysql -uroot -p
# 创建用户
create user 'slave'@'%' identified with mysql_native_password by 'root123';
# 授权
grant replication slave on *.* to 'slave'@'%';
# 刷新权限
flush privileges;
7.从数据库端验证主数据库slave用户是否可用
# 在从数据库端(192.168.8.101)
# 验证主数据库slave用户是否可用
mysql -uslave -p -h192.168.8.100 -P3306
8.配置主从节点信息
# 在主数据库端(192.168.8.100)
# 查询服务ID及Master状态
# 登录
mysql -uroot -p
# 查询server_id是否可配置文件中一致
show variables like 'server_id';
# 若不一致,可设置临时ID(重启失效)
set global server_id = 100;
# 查询Master状态,并记录 File(对应下一步中的master_log_file)
# Position (对应下一步中的master_log_pos)的值
show master status;
# 注意:执行完此步骤后退出主数据库
# 防止再次操作导致 File 和 Position 的值发生变化
9.在从数据库端设置同步
# 在从数据库端(192.168.8.101)
# 登录
mysql -uroot -p
# 查询server_id是否可配置文件中一致
show variables like 'server_id';
# 若不一致,可设置临时ID(重启失效)
set global server_id = 101;
# 设置主数据库参数(用上一步创建的slave用户及密码)
change master to
master_host='192.168.8.100',
master_port=3306,
master_user='slave',
master_password='root123',
master_log_file='mysql-bin.000001',
master_log_pos=828;
# 开始同步
start slave;
# 查询Slave状态
show slave status\G;
# 查看是否配置成功
# 查看参数 Slave_IO_Running 和 Slave_SQL_Running 是否都为yes,则证明配置成功。若为no,则需要查看对应的 Last_IO_Error 或 Last_SQL_Error 的异常值
# 若出现错误,则停止同步,重置后再次启动
stop slave;
reset slave;
start slave;
# 可以在从服务器my.cnf中添加
slave_skip_errors = ALL # 跳过错误,继续同步
# 重启MySQL服务
systemctl restart mysqld
10.测试主从复制,主服务上执行
# 在主数据库端(192.168.8.100)
mysql -uroot -p
# 创建test库,t1表,添加测试数据
create database test;
use test;
create table t1(id int,name varchar(30));
insert into t1(id,name) values(1,"aaa");
11.测试主从复制,从服务器上执行
# 在从数据库端(192.168.8.101)
mysql -uroot -p
# 查看是否同步数据
show databases;
use test;
show tables;
select * from t1;
十、GTID 方案
1.GTID 是什么?
GTID 的全称是 Global Transaction Identifier,全局事务 ID,当一个事务提交时,就会生成一个 GTID,相当于事务的唯一标识。
GTID 是 MySQL 数据库中用于唯一标识每个事务的机制,主要应用于主从复制场景,能简化复制配置、提高故障转移效率。
GTID 长这样:
c5d74746-d7ec-11ec-bf8f-0242ac110002:1
结构:
GTID=server_uuid:gno
GTID由两部分组成,格式为:source_id:transaction_id
- source_id:通常是生成事务的主库的服务器UUID(可通过show variables like 'server_uuid'查看),用于区分不同的数据库实例。
- transaction_id:是在该主库上生成的事务的序列号,从1开始递增。
例如,8a8b8c8d-8e8f-8a8b-8c8d-8e8f8a8b8c8d:100 就是一个GTID,其中8a8b8c8d-8e8f-8a8b-8c8d-8e8f8a8b8c8d是source_id,100是transaction_id。
2、GTID的工作原理
- 事务生成:主库上执行的每个事务都会被分配一个唯一的GTID,该GTID会随着事务一起记录到二进制日志(binlog)中。
- 复制传输:从库通过I/O线程将主库的binlog传输到本地的中继日志(relay log),同时也会获取到事务对应的GTID。
- 事务执行与记录:从库的SQL线程读取中继日志中的事务并执行,执行完成后,会将该GTID记录到
gtid_executed系统变量中,用于标识已经执行过的事务。 - 冲突避免:当主从切换或有新的从库加入时,新的主库会根据从库的
gtid_executed来判断哪些事务需要被发送,确保从库不会重复执行已经执行过的事务。
3、GTID的优势
- 简化复制配置:在配置主从复制时,不再需要指定二进制日志文件名和位置,只需启用GTID并正确配置相关参数,从库就能自动找到需要同步的起点。
例如,传统方式配置从库需要执行
change master to master_log_file='xxx', master_log_pos=xxx,而使用GTID后,只需change master to master_auto_position=1。 - 便于故障转移:当主库发生故障需要切换到从库时,通过查看各从库的
gtid_executed,可以快速确定哪个从库拥有最新的事务,从而选择最合适的从库作为新的主库,减少数据丢失的风险。 - 提高事务追踪能力:每个事务都有唯一的GTID,通过GTID可以方便地在主从库之间追踪事务的执行情况,便于排查复制过程中出现的问题。
4、GTID的相关参数
gtid_mode:用于启用或配置GTID模式,取值包括OFF(禁用)、ON(启用)、ON_PERMISSIVE(允许混合模式,新事务用GTID,旧事务不用)、OFF_PERMISSIVE(逐步禁用,旧事务继续用GTID,新事务不用)。通常设置为ON以完全启用GTID。enforce_gtid_consistency:确保事务的执行符合GTID的一致性要求,防止出现无法被GTID正确跟踪的事务,取值为ON(启用)或OFF(禁用),启用GTID时需设置为ON。gtid_executed:记录从库已经执行过的GTID集合。gtid_purged:记录已经被 purge 掉的GTID集合,即这些GTID对应的binlog已经被删除。
5、使用GTID的注意事项
- 避免非事务性操作:GTID主要追踪事务性操作,对于非事务性操作(如
CREATE TABLE ... SELECT在某些情况下)可能会导致GTID不一致,需要谨慎使用。 - binlog格式设置:建议将
binlog_format设置为ROW格式,因为STATEMENT格式可能会导致一些语句在主从库执行结果不一致,进而影响GTID的准确性。 - 谨慎处理GTID集合:手动修改
gtid_executed或gtid_purged可能会导致复制异常,除非明确了解后果,否则不要随意修改。 - 升级兼容性:在MySQL版本升级过程中,需要确保GTID相关参数的配置在不同版本之间兼容,避免出现复制中断等问题。
总之,GTID是MySQL主从复制中的一项重要技术,通过为每个事务分配唯一的全局标识符,极大地简化了复制管理和故障转移流程,提高了数据库系统的可靠性和可维护性。
6、如何启用 GTID
修改主库和从库的配置文件:
vim /etc/my.cnf
[mysqld]
...
## 在配置文件中添加GTID配置
gtid_mode=on
enforce_gtid_consistency=on
解释:
gtid_mode=on #GTID 是一个全局唯一的事务标识符,用于标识数据库集群中的事务。启用 GTID 后,每个事务都会被分配一个唯一的 GTID。
enforce_gtid_consistency=on #当启用 GTID 后,该选项用于强制要求从库只能复制具有与主库一致的 GTID 链的事务,以确保数据一致性。
从库配置同步的参数:
## 格式
CHANGE MASTER TO
MASTER_HOST=$host_name,
MASTER_PORT=$port,
MASTER_USER=$user_name,
MASTER_PASSWORD=$password,
master_auto_position=1;
## 例如:
change master to
master_host='192.168.8.100',
master_port=3306,
master_user='slave',
master_password='root123',
master_auto_position=1;
其中 master_auto_position 标识主从关系使用的 GTID 协议。
相比之前的配置,MASTER_LOG_FILE 和 MASTER_LOG_POS 参数已经不需要了。
7.GTID 同步方案
GTID 同步的原理图。
GTID 方案:主库计算主库 GTID 集合和从库 GTID 的集合的差集,主库推送差集 binlog 给从库。
当从库设置完同步参数后,主库 A 的GTID 集合记为集合 x,从库 B 的 GTID 集合记为 y。从库同步的逻辑如下:
- 从库 B 指定主库 A,基于主备协议简历连接。
- 从库 B 把集合 y 发给主库 A。
- 主库 A 计算出集合 x 和集合 y 的差集,也就是集合 x 中存在,集合 y 中不存在的 GTID 集合。比如集合 x 是 1~100,集合 y 是 1~90,那么这个差集就是 91~100。这里会判断集合 x 是不是包含有集合 y 的所有 GTID,如果不是则说明主库 A 删除了从库 B 需要的 binlog,主库 A 直接返回错误。
- 主库 A 从自己的 binlog 文件里面,找到第一个不在集合 y 中的事务 GTID,也就是找到了 91。
- 主库 A 从 GTID = 91 的事务开始,往后读 binlog 文件,按顺序取 binlog,然后发给 B。
- 从库 B 的 I/O 线程读取 binlog 文件生成 relay log,SQL 线程解析 relay log,然后执行 SQL 语句。
GTID 同步方案和位点同步的方案区别是:
- 位点同步方案是通过人工在从库上指定哪个位点,主库就发哪个位点,不做日志的完整性判断。
- 而 GTID 方案是通过主库来自动计算位点的,不需要人工去设置位点,对运维人员友好。
在线将传统复制切换到GTID复制
## 在主从库执行
set global enforce_gtid_consistency=WARN;
set global enforce_gtid_consistency=on;
set @@GLOBAL.GTID_MODE = OFF_PERMISSIVE;
## 先在从库上执行
set @@GLOBAL.GTID_MODE = ON_PERMISSIVE;
## 然后在主库执行
set @@GLOBAL.GTID_MODE = ON_PERMISSIVE;
# 查看是否为0,等于0是表示所有连接都转为gtid复制
show status like 'ONGOING_ANONYMOUS_TRANSACTION_COUNT';
# 主从库执行
set global gtid_mode=on;
# 从库执行
stop slave;
change master to master_auto_position=1;
start slave;
## 永久生效,记得更改配置文件
在线将GTID的环境切换到非GTID
# 从库执行
stop slave;
change master to master_auto_position=0;
start slave;
# 主从库执行
set @@GLOBAL.GTID_MODE = ON_PERMISSIVE
# 主库执行
set @@GLOBAL.GTID_MODE = OFF_PERMISSIVE
# 这个时候已经从gtid转到传统复制了,不过还是中间状态
# 在从库执行
set @@GLOBAL.GTID_MODE = OFF_PERMISSIVE
# 主从库执行
select @@GLOBAL.GTID_OWNED;
# 是不是为空
# 主库执行
set global gtid_mode=0;
# 主库执行
set global enforce_gtid_consistency=off;
## 永久生效,记得配置文件修改