要理解 Ceph 与 分布式存储 的关系,首先需要明确:分布式存储是一个广义的技术范畴,而 Ceph 是分布式存储领域中最主流、功能最全面的开源实现之一。下面将从“分布式存储基础”切入,逐步深入 Ceph 的架构、特性、优势,并对比其他方案,最终说明其应用场景。
一、分布式存储基础:概念与核心价值
在了解 Ceph 之前,需先明确“分布式存储”的本质——它解决了传统集中式存储(如 SAN、NAS 设备)的瓶颈问题。
1. 什么是分布式存储?
分布式存储是将数据分散存储在多个独立的服务器节点(物理机/虚拟机) 上,通过软件层实现节点协同、数据冗余、故障自愈的存储系统。其核心是“用‘集群’替代‘单设备’”,从而突破单设备的容量、性能和可靠性限制。
对比传统集中式存储,两者的核心差异如下:
| 维度 | 集中式存储(如 SAN/NAS 设备) | 分布式存储(如 Ceph) |
|---|---|---|
| 硬件形态 | 专用硬件设备(厂商锁定) | 通用 x86 服务器(硬件解耦) |
| 扩展性 | 纵向扩展(升级单设备硬件,上限低) | 横向扩展(新增节点,容量/性能线性增长) |
| 可靠性 | 依赖设备自身冗余(如 RAID),单点风险高 | 跨节点数据冗余(副本/纠删码),无单点故障 |
| 成本 | 硬件成本高,维护费用贵 | 通用硬件,成本低,开源方案无license(许可)费 |
| 灵活性 | 功能固定(如 SAN 只支持块存储) | 支持多存储类型(块/文件/对象) |
2. 分布式存储的核心特性
无论何种分布式存储方案(包括 Ceph),都需具备以下关键能力:
- 横向扩展(Scale-Out):新增节点即可扩展存储容量和 IO 性能,无需停机。
- 数据冗余与容错:通过“副本”(多存几份)或“纠删码”(拆分数据+校验块)实现数据不丢失,节点故障后自动恢复。
- 一致性保障:确保多节点读写数据时的准确性(如强一致性、最终一致性,视场景选择)。
- 自愈能力:自动检测故障节点,将故障节点的数据迁移到健康节点,无需人工干预。
- 弹性伸缩:支持动态增删节点,适配业务流量的波动(如云计算场景的弹性需求)。
二、Ceph 详解:分布式存储的“全能选手”
Ceph 是 2006 年由 Sage Weil 发起的开源分布式存储项目,目前由 Red Hat 主导维护,是唯一支持“块存储、文件存储、对象存储”三种类型的统一分布式存储系统,也是云计算(如 OpenStack、K8s)的首选存储后端之一。
1. Ceph简介和特性

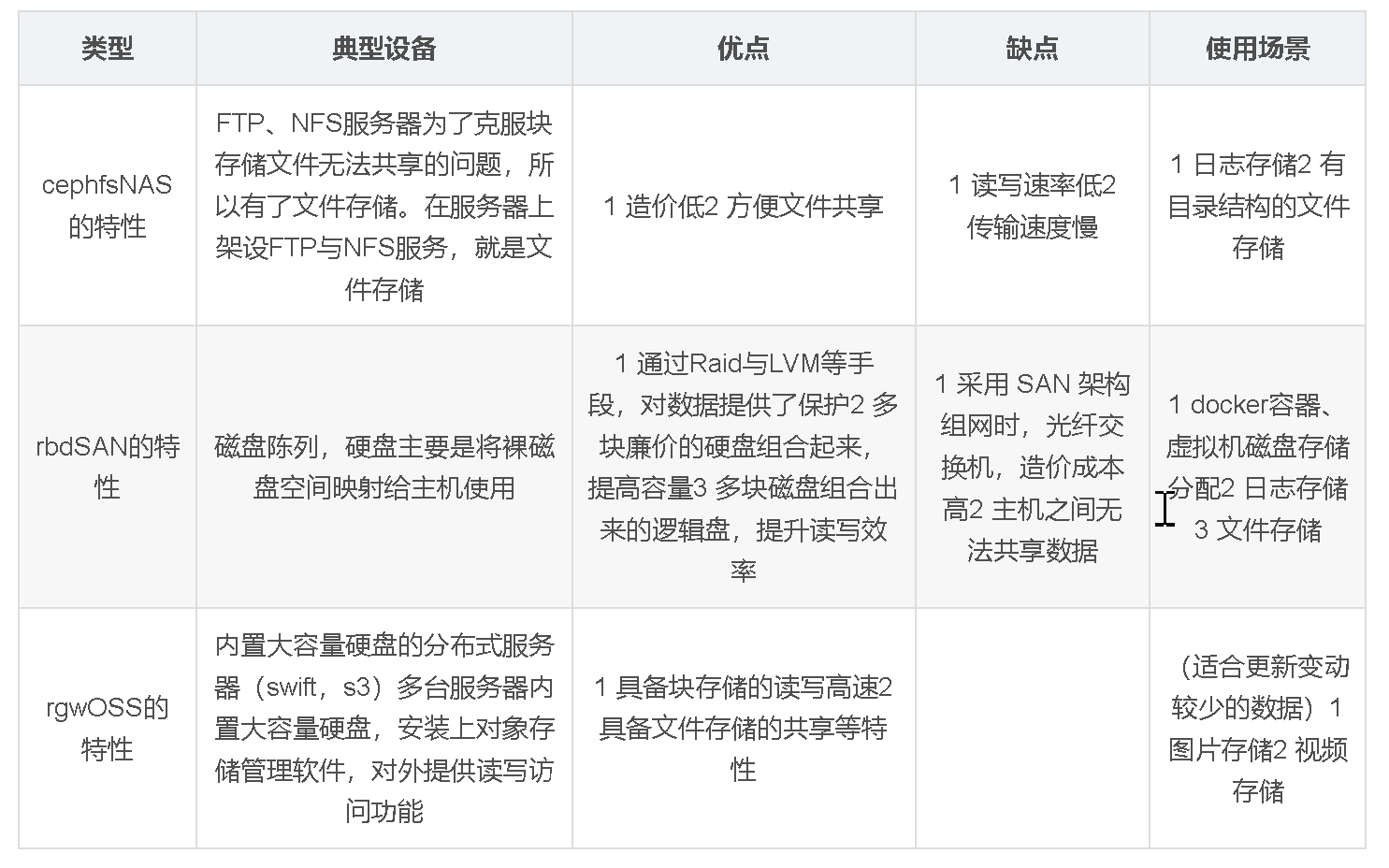
Ceph是一种开源的软件定义存储系统。它也是一款以对象存储技术(独立存储技术)为核心,并在此基础之上实现块存储、文件存储的分布式存储系统。
Ceph可以实现NAS和SAN以及OSS对象存储功能。
Ceph诞生于2004年,最早致力于开发下一代高性能分布式文件系统的项目。Ceph可以部署在任意x86服务器上工作,具有良好的扩展性、兼容性和可靠性。
它能对外提供文件系统服务(cephfs)、块服务(rbd)和对象存储服务(rgw),是一种统一存储系统。Ceph架构支持海量数据存储,集群可以扩展至PB容量,系统本身无热点数据,数据寻址依赖计算而不是查找,并能做到数据状态自维护,数据自修复,是一款优秀的分布式存储系统。
Ceph 项目最早起源于 Sage 就读博士期间的工作(最早的成果于2004年发表,论文发表于2006年),并随后贡献给开源社区。
ceph官网:https://ceph.com/en/
ceph文档官网:https://docs.ceph.com/en/latest
github地址:https://github.com/ceph/ceph
2.为什么 Ceph 这么火?
- 功能强大:Ceph 能够同时提供对象存储(访问是基于通过URL的方式),块存储(SAN)和文件系统存储(NAS)三种存储服务的统一存储架构
- 可扩展性:Ceph 得以摒弃了传统的集中式存储元数据寻址方式,通过内置Crush算法的寻址操作,有相当强大的扩展性
- 高可用性:Ceph 数据副本数量可以由管理员自行定义,并可以通过 Crush 算法指定副本的物理存储位置以分割故障域,支持数据强一致性的特性也使得Ceph具有了高可靠性,可以忍受多种故障场景并自动尝试
- 并行修复:RadosGW、RBD和CephFS都是RADOS存储服务的客户端,它们把RADOS的存储服务接口(librados)分别从不同的角度做了进一步的抽象,因而各自适用于不同的应用场景。
3.Ceph运行原理
Ceph 把每一个待管理的数据流(例如一个文件)切分成一到多个固定大小的对象数据,并以其为原子单元完成数据存取。(横向扩展方便,内置了副本技术,副本数默认是3。单机是无法实现Ceph,只能通过集群来实现Ceph)
Ceph通过内部的 crush 机制,实时方式计算出一个文件应该存储到哪个存储对象里面,从而实现快速查找对象的一种方式。
对象数据的底层服务是由多个主机(Host)组成的存储集群,该集群也称之为 RADOS(Reliable Automatic Distributed Object Store)存储集群,即可靠,自动化,分布式对象存储系统。
librados 是 RADOS 存储集群的 API,它支持 C、C++、Java、Python、Ruby 和PHP等编程语言。

在RADOS集群之上,Ceph构建了块存储、文件存储和对象存储等存储形态。由于RADOS集群本身是以对象为粒度进行数据存储的,因此上述三种存储形态,在最终存储数据的时候都划分为对象。也就是说,Ceph 将三种三种存储类型统一在一个平台中,从而实现了更加强大的适用性。
通俗解释:
要理解Ceph的运行原理,我们可以把它类比成一个“分布式的智能仓库系统”——不需要中心化的管理员(比如传统存储的“存储服务器”),而是让仓库里的每个“员工”(硬件节点)协同工作,既能存东西、找东西,还能自动处理故障,最终实现“存得稳、找得快、能扩容”的目标。
先明确Ceph的核心定位:它是一个统一存储系统,能同时提供三种存储服务(就像仓库能存零散包裹、整箱货物、还能实时传递文件):
- 块存储(类似U盘/硬盘,给虚拟机、数据库用);
- 文件存储(类似电脑文件夹,给服务器共享文件用);
- 对象存储(类似云盘,给APP、备份用,按“对象”(文件+描述信息)管理)。
下面用“仓库类比”拆解它的3个核心组件和运行逻辑:
| 角色名称 | 类比仓库里的角色 | 核心作用 |
|---|---|---|
| OSD | 仓库保管员(存东西的) | 1. 实际存数据(类似保管员管货架); 2. 自动检查数据是否损坏(定期“盘点”); 3. 数据坏了自动修复(发现丢了,从同事那复制补全)。 |
| Monitor | 仓库调度员(记信息的) | 1. 记录整个集群的“通讯录”(哪个OSD在、存了什么); 2. 监控集群状态(谁坏了、谁满了); 3. 确保所有员工信息同步(大家按同一套规则干活)。 |
| MDS | 仓库导购员(仅文件存储用) | 1. 管理文件的“目录结构”(比如“/办公文件/2024年/”); 2. 帮用户快速找到文件位置(类似导购指路,不用自己遍历所有货架)。 |
传统存储是“把文件存在某一台服务器的硬盘里”,一旦服务器坏了,数据就丢了。Ceph的思路是“不把鸡蛋放一个篮子里”,具体分3步:
1. 第一步:把数据“打碎”成小“块”(PG)
比如你要存一个10GB的文件,Ceph不会直接存整个文件,而是先把它拆成很多32MB/64MB的小“块”(默认64MB,可配置)——就像把大箱子拆成小包裹,方便分散存放。
这些小“块”会被分到不同的“逻辑分组”(叫PG,Placement Group, placement 是“放置”的意思)。比如1000个小“块”,可能分到100个PG里,每个PG管10个小“块”。
→ 为什么要分PG?因为直接管理1000个小“块”太麻烦,用PG当“中间层”,只需要管理100个PG,效率更高(类似仓库把“货架按区域分组”,管“区域”比管每个货架省事)。
2. 第二步:给每个PG“找3个保管员(OSD)”存副本
Ceph默认会给每个PG找3个不同的OSD(可以理解为“3个不同的货架”),把PG里的小“块”存3份——这就是“多副本机制”,确保即使1个OSD坏了,还有2个备份,数据不丢。
那怎么找这3个OSD?靠Monitor的“通讯录”:
- Monitor知道所有OSD的位置、负载(比如哪个OSD空闲);
- 按“尽量分散”的规则(比如3个OSD不在同一台服务器、不在同一个机房),避免“一坏全坏”;
- 找到后,把PG的3个“存放地址”记下来,同步给所有员工。
3. 第三步:OSD存数据,还定期“对账”
3个OSD拿到PG的小“块”后,就存在自己的硬盘里(可以是机械硬盘、SSD)。同时,它们会定期互相“对账”:
- 比如OSD1问OSD2:“你存的PG123的第5个小‘块’是不是xxx?”;
- 如果发现某OSD的数据坏了(比如硬盘出错),其他OSD会自动把好的数据复制过去,补全3个副本——这就是Ceph的“自愈能力”,不用人工干预。
当你要读取之前存的文件时,Ceph不用“遍历所有OSD”,而是靠一套“快速定位逻辑”,类似“查快递单号找包裹”:
1.你提供“文件的唯一标识”(比如对象存储的“对象ID”、块存储的“块编号”);
2.Ceph先根据这个“标识”,计算出它属于哪个PG(比如“对象ID=12345”→ 计算得“属于PG123”);
3.查Monitor维护的“PG-OSD映射表”(知道PG123存放在OSD1、OSD2、OSD3上);
4.直接找这3个OSD中的任意一个(通常找负载最低的),读取数据,拼成完整的文件返回给你。
→ 整个过程不用经过“中心化服务器”,每个节点都知道怎么找数据,所以速度快,而且节点越多,找数据的“路径”越多,效率越高。
传统存储扩容很麻烦(比如要加一台新的存储服务器,还要手动迁移数据),但Ceph扩容像“仓库加新货架”一样简单:
1.新增一台服务器,在上面启动一个OSD进程(相当于“新招一个保管员,加一个新货架”);
2.新OSD会主动向Monitor“报到”,Monitor把它加入“通讯录”;
3.Monitor会发现“新OSD空闲”,就自动把原来PG的副本“挪一部分”到新OSD上(比如把某PG的第3个副本从旧OSD移到新OSD);
4.迁移完成后,集群的总容量增加了,而且负载也分散到新OSD上——整个过程不影响正在读写的数据,是“在线扩容”。
用“仓库类比”总结,Ceph的优点很直观:
1.数据不丢:3副本+自愈,坏了自动补;
2.找得快:靠PG+映射表,不用遍历,定位快;
3.扩容方便:加OSD就像加货架,自动分担负载;
4.功能全:一块集群能同时提供块、文件、对象存储,不用搭3套系统;
5.成本低:可以用普通服务器+普通硬盘,不用买昂贵的专用存储设备。
简单来说,Ceph就是一个“自己管自己的智能仓库”:员工(OSD)自己存数据、自己修故障,调度员(Monitor)自己记信息、自己分任务,导购员(MDS)自己管目录,最终实现“存得稳、找得快、能扩容”的目标。

OSD - 对象存储守护进程 (OSD) 存储对象。
- OSD 是在存储服务器上运行的进程。OSD 负责 管理单个存储单元,通常是单个磁盘。
MON - 是Ceph监控组件(Monitor,简称 MON)负责维护集群的状态和元数据信息。
LIBRADOS - 通过自编程方式实现数据的存储能力
RADOSGW - 通过标准的RESTful接口,提供一种云存储服务
RBD - 将ceph提供的空间,模拟成一个个的独立块设备。当ceph环境部署完成之后,服务端就准备好RBD接口
CFS - 通过一个标准的文件系统接口来进行数据的存储

参考地址:https://docs.ceph.com/en/pacific/_images/stack.png
3.Ceph 组件

4.Ceph 网络模型
Ceph 生成环境中一般分为两个网段:
- 公有网络:用于用户的数据通信,用户通过公有网络来访问Ceph集群
- 集群网络:用于集群内部的管理通信,Ceph集群组件之间的通信网络,例如:数据交换

5.Ceph 版本
每个Ceph的版本都有一个英文的名称和一个数字形式的版本编号。
第一个Ceph版本编号是 0.1,发布于 2008 年 1 月,之后是 0.2,0.3,… 多年来,版本号方案一直没变。
2015 年 4月 0.94.1(Hammer 的第一个修正版)发布后,为了避免 0.99(以及0.100胡总1.00?),制定了新的策略。
x 将从 9 算起,它代表版本名称 Infernalis (I 是第九个字母),这样第九个发布周期的第一个开发版就是 9.0.0;后续的开发版依次是 9.0.1、9.0.2 等等
x.0.z - 开发版(测试环境,个人爱好可以使用)
x.1.z - 候选版(测试环境,个人爱好可以使用)
x.2.z - 稳定,修正版(生产环境使用)
Ceph 版本说明:
https://docs.ceph.com/en/latest/releases/

6.Ceph 部署方法介绍
由于Ceph组件众多以及环境复杂,所以官方提供了多种的快速部署工具和方法。
参考资料:
https://docs.ceph.com/en/pacific/install/

7. Ceph 的核心定位
Ceph 的设计目标是:用通用硬件构建一个高可用、高扩展、高性能的统一存储集群,打破传统存储“块、文件、对象”分离的格局,让一个集群满足企业的所有存储需求。
8. Ceph 的核心架构
Ceph 采用“三层架构”设计,从下到上分别是 RADOS(底层存储核心)、LIBRADOS(客户端接口)、上层存储服务(网关层),每层职责清晰,解耦灵活。
(1)最底层:RADOS(可靠的自主分布式对象存储)
RADOS(Reliable Autonomic Distributed Object Store)是 Ceph 的“心脏”,负责将数据以“对象”形式分散存储在集群节点中,并实现数据的复制、容错、自愈和负载均衡。它由两个核心组件构成:
- OSD(对象存储守护进程,Object Storage Daemon):
- 每个 OSD 对应一个物理/虚拟磁盘(或磁盘分区),是数据的“实际存储载体”。
-
职责:存储数据、处理数据读写请求、与其他 OSD 同步数据(实现副本)、向 Monitor 报告节点状态。
-
Monitor(监控守护进程):
- 维护整个 Ceph 集群的“集群地图(Cluster Map)”——记录 OSD 节点、存储池、数据副本策略等关键信息,是集群的“大脑”。
- 为保证自身高可用,Monitor 通常部署 3/5 个节点(奇数,避免脑裂),通过 Paxos 协议实现数据一致性。
此外,还有一个辅助组件 MGR(管理器守护进程,Manager Daemon):负责集群监控、性能统计、告警、API 管理(如对接 Prometheus/Grafana 可视化),是 Ceph Luminous 版本后新增的核心组件,减轻了 Monitor 的负担。
(2)中间层:LIBRADOS(客户端开发库)
LIBRADOS 是封装了 RADOS 核心能力的客户端库(支持 C/C++、Python、Java 等语言),允许应用程序直接调用 RADOS 的接口访问存储(无需通过上层网关),是 Ceph 灵活性的关键。例如,OpenStack 的 Cinder 组件就是通过 LIBRADOS 直接与 Ceph 交互。
(3)最上层:存储服务网关(支持三种存储类型)
Ceph 通过不同的网关接口,将 RADOS 的能力封装为企业常用的存储类型,满足不同业务需求:
| 网关组件 | 支持的存储类型 | 核心用途与特性 |
|---|---|---|
| RBD(块设备网关) | 块存储 | - 提供可挂载的“虚拟块设备”(类似硬盘),支持快照、克隆、瘦分配。 - 适配场景:虚拟机磁盘(如 OpenStack Nova、K8s PV)、数据库(MySQL、PostgreSQL)。 |
| CephFS(文件系统网关) | 文件存储 | - 提供 POSIX 兼容的分布式文件系统(类似 NFS),支持目录、权限管理,可直接挂载到 Linux/Windows 主机。 - 适配场景:共享存储(如应用日志、大数据任务的共享数据)。 |
| RGW(对象网关) | 对象存储 | - 提供兼容 S3/Swift API 的对象存储服务(以“桶(Bucket)”和“对象(Object)”为单位存储数据)。 - 适配场景:海量非结构化数据(如图片、视频、备份文件)、云原生应用的对象存储需求。 |
3. Ceph 的核心优势
Ceph 能成为分布式存储的主流方案,源于其独特的设计优势:
- 统一存储架构:一个集群同时支持块、文件、对象存储,避免企业部署多套存储系统的复杂度和成本。
- 极致的扩展性:理论上支持数千个 OSD 节点,存储容量可达 PB 甚至 EB 级,性能随节点增加线性增长。
- 高可靠性:
- 支持副本(默认 3 副本)和纠删码(如 EC 4+2:4 个数据块+2 个校验块,比副本更省空间)两种冗余策略。
- 故障自愈:OSD 节点下线后,Monitor 自动触发数据迁移,无需人工干预。
- 强一致性:默认提供强一致性(数据写入成功后,所有节点读取到的都是最新数据),满足金融、数据库等对数据准确性要求高的场景。
- 硬件解耦:基于通用 x86 服务器,支持 SATA、SAS、SSD、NVMe 等各类磁盘,无需依赖专用硬件,降低成本。
- 开源生态成熟:与云计算生态(OpenStack、Kubernetes、Docker)、大数据生态(Hadoop、Spark)深度集成,社区活跃,文档丰富。
三、Ceph 与其他分布式存储方案的对比
为了更清晰地理解 Ceph 的定位,下面将其与开源领域的其他主流分布式存储方案对比:
| 方案 | 支持存储类型 | 架构复杂度 | 核心优势 | 适用场景 | 不足 |
|---|---|---|---|---|---|
| Ceph | 块+文件+对象 | 较高 | 统一存储、扩展性强、生态完善 | 云计算、企业级混合存储需求 | 部署维护复杂,需专业知识 |
| GlusterFS | 文件存储(主打) | 低 | 部署简单、轻量、文件共享高效 | 中小规模文件共享(如日志存储) | 不支持块/对象存储,性能上限低 |
| Swift | 对象存储(主打) | 中 | 轻量、S3兼容、适合海量对象 | 纯对象存储场景(如备份) | 不支持块/文件存储 |
| HDFS | 文件存储(主打) | 中 | 大数据批处理优化、高吞吐 | Hadoop/Spark 大数据场景 | 不支持块/对象存储,随机读写性能差 |
四、Ceph 的典型应用场景
1.云计算基础设施存储:
- 作为 OpenStack 的核心存储后端:RBD 为 Nova 虚拟机提供块磁盘,CephFS 为实例提供共享文件存储,RGW 为对象存储服务提供支持。
- 作为 Kubernetes 的持久化存储(PV/PVC):RBD 提供块存储,CephFS 提供文件存储,满足容器化应用的持久化需求。
2.企业级核心业务存储:
- 替代传统 SAN 设备:为数据库(MySQL、Oracle)、中间件(Redis、Kafka)提供低延迟、高可靠的块存储。
- 企业共享存储:通过 CephFS 为办公系统、开发测试环境提供文件共享服务。
3.海量非结构化数据存储:
- 通过 RGW 存储海量图片、视频、日志、备份文件,支持 S3 API,可无缝对接业务系统或备份工具(如 Veeam)。
4.大数据与 AI 场景:
- 与 Hadoop 集成:将 Ceph 作为 HDFS 的替代存储,支持大数据批处理(Spark)和 AI 训练(TensorFlow)的海量数据读写。
五、Ceph 的挑战与注意事项
1.部署维护门槛高:Ceph 组件多(OSD/Monitor/MGR/网关),配置参数复杂,需专业运维人员进行部署、调优和故障排查(可通过工具如 Cephadm、Rook 降低复杂度)。
2.对硬件的要求:
- 网络:需万兆以太网(甚至 InfiniBand),避免网络成为性能瓶颈(尤其是副本同步、数据迁移时)。
- 磁盘:OSD 节点建议使用 SSD 作为缓存盘(加速读写),HDD 作为数据盘(降低成本);避免使用 RAID(Ceph 自身已实现数据冗余)。
3.性能调优复杂:需根据业务场景(如块存储侧重低延迟,对象存储侧重高吞吐)调整参数(如副本数、缓存策略、IO 调度算法)。
六、总结
- 分布式存储是解决“海量数据存储、高可用、高扩展”的核心技术方向,而 Ceph 是该领域的“全能型选手”——通过统一架构支持三种存储类型,兼具扩展性、可靠性和生态兼容性。
- 尽管 Ceph 存在部署维护复杂的问题,但凭借其“一站式存储”的优势,已成为开源分布式存储的事实标准,广泛应用于云计算、企业 IT、大数据等领域。
- 对于需要“混合存储需求”(如同时需要块+对象+文件存储)或“大规模扩展”的场景,Ceph 是目前最优的开源选择之一。